本文将从当今的生物信息大数据出发,提出有别于传统方法的工业酶筛选新思路。在此基础上,结合本公司的最新研究成果,简要介绍几种典型工业酶的设计和挖掘新策略。
1.从已测序的微生物基因组中挖掘目标酶基因
随着基因测序技术的飞速发展,越来越多的微生物基因组被测序,其中有一部分基因的开放阅读框所编码的酶潜在功能已被预测,但可能未经实验证实;另有大量开放阅读框所编码的酶信息仍未被注释或实验研究。一方面可以直接将已注释的假想酶基因进行克隆表达,并通过活力检测来获得所需的候选生物催化剂;另一方面还可通过对未注释酶的开放阅读框进行比对分析,并与已报道类似酶的保守序列进行比较,找到具有潜在功能的目标新酶编码序列,进而通过克隆表达来获得结构/功能全新的目标生物催化剂。后者的风险相对较大(成功率较低),但创新性更强,比较容易获得知识产权。
2.基于探针酶序列的基因挖掘
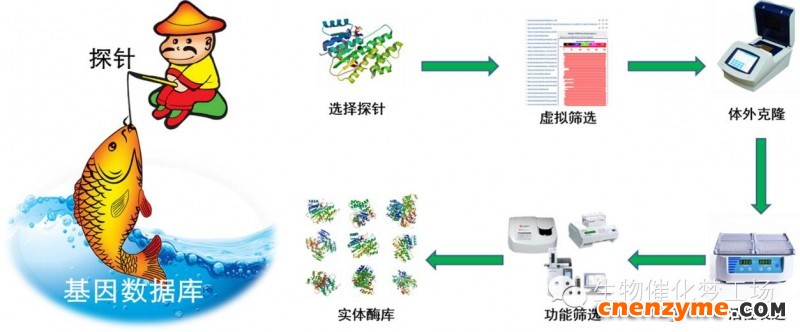
图1 基于探针序列信息从基因组数据库中挖掘新酶的技术路线图
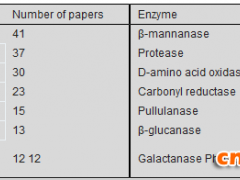
当催化某类反应的相关酶基因(或多肽)序列已有文献报道后,就可以利用此序列作为基因探针(或称模板)在公共基因组数据库中进行检索,找到与探针序列具有一定同源性的候选酶基因,进而根据检索到的基因序列设计引物,利用PCR扩增法获得编码这些酶的DNA,并将它们进行克隆表达,最后通过目标底物进行活性筛选,即可能获得所需要的具有特定催化功能的生物催化剂(图1)。例如,本公司从基因组数据库中挑选、规划了一千多种结构多样、功能各异的醇脱氢酶/羰基还原酶(图2),目前已经成功制备了600多种冻干酶制剂,可以满足我国医药化工企业对部分工业生物催化剂的定制服务需求。
图2 醇脱氢酶/羰基还原酶“千酶库”的分子进化树
3.基于序列和结构信息相结合的新酶基因挖掘
从已测序微生物基因组中直接克隆酶的基因并进行异源表达,或者基于探针酶的序列在基因数据库中挖掘目标酶的技术业已成熟并取得了较好的应用效果,不过其前提条件是未知酶的功能已经被预测注释,或者催化特定底物转化的酶基因序列已经公开报道。然而,针对某些特定的底物,仅仅基于催化类似反应的酶的序列信息所挖掘得到的酶,往往无法催化目标底物的转化,或者虽能催化反应却不能达到预期的效果。如果能将基因挖掘和结构分析等相关信息结合起来,将有望显著提高基因挖掘的效率。
展望
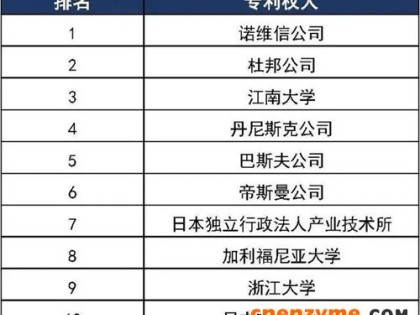
2015年7月,美通社在线发布《2014年全球工业酶行业研究报告及未来三年预测》。近年来,全球工业酶制剂市场规模逐年增加,年产值增长率为5%,2014年已达42.2亿美元的规模。目前,全球工业酶市场基本上是寡头垄断。在2014年,诺维信作为工业用酶巨头,占据了44%的市场份额;而杜邦公司和DSM分别占有为20%和6%的市场份额。全球各地区需求呈现较大差异,欧洲和北美地区对工业酶的需求量最大,占据80%;而中国仅占9.4%。
在市场需求扩大和政策利好的双重刺激下,2014年中国的工业酶制剂产量已达116.57万吨并保持10%年产量增长趋势,预计2017年产量将达到154.87吨。通过引进国外先进的设备、优良的菌株以及新型酶制剂的开发,中国已开始进入酶制剂工业的快速发展期。但在酶制剂研发的原始创新方面尚有一定差距,多数企业的自主开发能力还十分有限。
若能抓住当今大数据、互联网+的时代机遇,充分利用好全球共享共用的生物信息资源,掌握工业酶设计和改造的核心技术,并将之转化为具有我国自主知识产权的工业酶实体资源,则可望从源头上引领我国生物催化学科的快速崛起,推进生物制造产业的高起点和跨越式发展。